In the initial two sections of this series (part 1 & part 2), we have established the strategy behind the enterprise AI integration, including selecting the high-impact use cases, creating a business case, and governance. This third part will pivot to infrastructure and implementation to scale up AI solutions. This is where high-flying AI visions are coming to terms with the physical realities of information, skills, technology stacks, and implementation procedures.
An effective infrastructure strategy is also essential in making sure that your AI projects do not languish in the laboratory but rather provide value in production. We will explain how to formulate a data strategy (data readiness, pipelines, labeling, and governance) best, how to address the talent needed (hiring and upskilling roles like MLOps engineers and AI product owners), how to make the right tool and platform choices (build vs. buy decisions and open-source vs. vendor stacks), and how to make correct decisions regarding AI infrastructure (cloud vs. on-premise vs. hybrid).
Finally, we outline an implementation playbook that is intended to guide you through proof-of-concept experiments, pilot projects, and fully deployed systems, as well as continuous integration, testing, and monitoring. All along, we bring in the real-life perspectives and examples that help demonstrate what does (or does not) work in enterprise AI integration.
Defining a Data Strategy for AI Success

The quality of any AI integration in an enterprise depends on the data used. The clear data strategy will ensure that your organization’s data is prepared, trustworthy, and responsibly handled to power AI models. Like they say, “garbage in, garbage out.” Insufficient data will result in poor AI models, erode stakeholder trust, and undermine even the most effective algorithms. Organizations do not realize the magnitude of work involved in preparing data to be AI-ready. The most essential elements of an effective data strategy in AI are:
Data Readiness & Quality
Pre-judge on the status of your data sources. The failure of vast numbers of AI projects is that the data on which they are ultimately based is not comprehensive, uniform, or locked away in legacy systems. Standardize, cleanse, and enrich the data prior to model building. This implies taking care of missing values and outliers, normalizing formats, and constantly checking the freshness and drift of data.
Top companies do not view data preparation as a project but rather as a process. E.g., Motivus (an AI consulting firm) uses continual data cleansing pipelines, which keep running to pick up anomalies as new data arrives, not one upfront cleanse. Good data pipelines are able to ensure your AI models are being trained on good, up-to-date data, and not stale or bad data.
Data Pipelines & Integration
To power the AI applications, scalable data pipelines must have the capability to ingest and process data sources (databases, APIs, streams of events) in real-time and batch processing. You want to have growth-oriented and reliable pipelines to perform the ETL jobs and not just do one-off ones. What makes a pipeline “AI-ready”? It must be able to work with varied types of data (structured tables, text, images, etc.), be integrated with cloud- or on-premise platforms, and consist of orchestration layers to operate easily.
Numerous prototypes using hard-coded data flows that are hand-built cannot withstand the levels of volume and variety required by an enterprise. To prevent this, design modular pipelines with a view towards scaling up in the future, e.g., use workflow orchestration tools (such as Apache Airflow or cloud-native services) and scalable storage/compute engines (data lakes, stream processors) that will allow you to scale as the volume of data grows. This base will not only support your first use case of AI but also others in future models and applications.
Data Labeling and Annotation
In the case of supervised machine learning applications, the data strategy should have data labeling plans, which are the transformation of raw data to training datasets with correct annotations. Regardless of whether you are labelling images to train a computer vision model or examples to train a customer service chatbot, enterprise organizations require processes (and potentially tools or vendors) to produce high-quality labels. There is a need to enact universal annotation standards and quality control to make sure that models learn based on correct information.
According to one of the providers of AI platforms, data should be carefully aligned and annotated, complete with understandable semantics, correct labels, and a clear lineage so that AI can indeed comprehend and use it. In other cases, where privacy or volume is a problem, synthetic data generation may be used to supplement the real data in order to obtain more labeled examples. The work is not to be underestimated: labeling is time-consuming, so start planning it early (in-house domain expertise or specialized data labeling services).
Data Governance & Security
Governance forms the foundation through which your data will be a trusted asset in the long run. This means implementing policies and systems that govern access to data, ensure data quality, protect data privacy, and ensure compliance before scaling AI enterprise-wide. Data ownership and stewardship: what are the responsibilities of the different types of datasets, and who has access to sensitive information? Implement the logging of data usage and role-based access controls. Model output lineage to source and consumption, so you can always see how a model input was produced.
Data strategy needs to incorporate compliance requirements (GDPR, HIPAA, industry) and should do so, especially because AI has the tendency to consolidate data across various systems in a way that may raise both privacy and ethics issues. As opposed to being a bureaucratic obstacle, good governance is, in fact, a key to AI success as it helps to instill confidence in data integrity and preserve an AI decision audit trail.
Among the most successful businesses, governance is a strategic concern, and they use contemporary data cataloging and observability solutions (e.g., Alation, Collibra, Azure Purview) to catalog data and track its quality continually. Security is also not a negotiating point: end-to-end protection of your data pipelines, encryption of sensitive data both at rest and in transit, and ensuring that the use of AI models does not bring new vulnerabilities.
Case Study – International Retailer
An international retailer had been trying to use AI to do demand forecasting and found that the historical sales data it required was held in three separate business units in incompatible formats. Data silos and inconsistency of this type are not uncommon – without an active data strategy, AI projects may be delayed or derailed as teams rush to locate, clean, and normalize data.
Enterprises that invest in data readiness up-front inventory all relevant sources of data (including those that may be referred to as dark data, such as unstructured documents or support emails), address any quality gaps, and build governance into their AI projects, thus providing the foundation that their projects need to succeed. Short answer: Enterprise AI integration begins long before model development; it begins with getting your data house in order.
A good data strategy not only enhances model performance but also develops a competitive advantage, as the quality data that is governed well is something that competitors cannot easily imitate.
Talent Needs: Building AI Expertise and Capacity
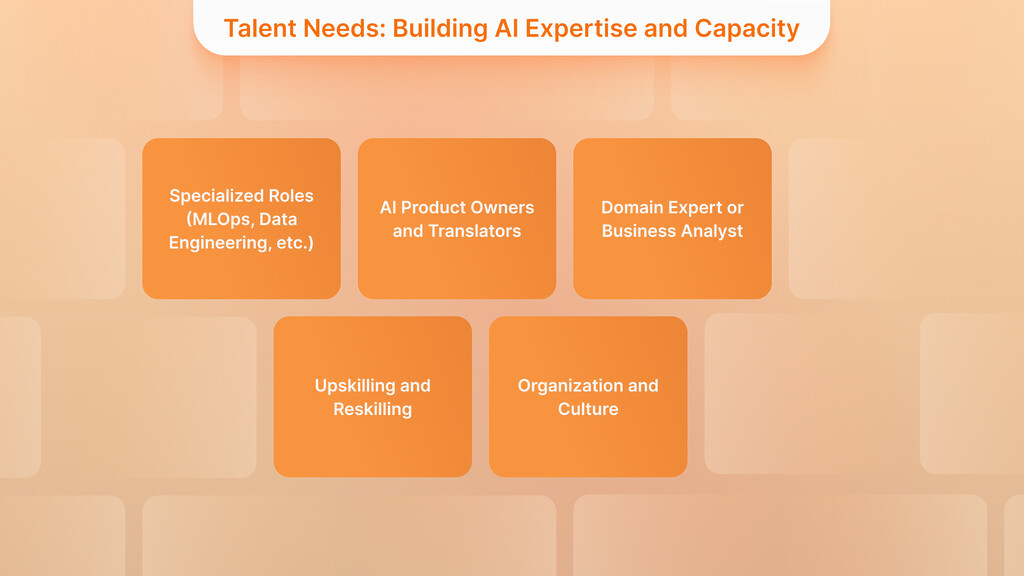
The deployment of AI on an enterprise level is not only a technical issue, but also an organizational one. To drive the integration of AI, there should be the appropriate talent and team structure to achieve success. This usually translates to combining new specialist tasks and up-skilling the available teams. Some of the considerations of key talent are:
Specialized Roles (MLOps, Data Engineering, etc.)
The transition of AI projects to production will increase the demand for specialized engineering jobs. On more conventional software projects, a small group can typically carry a solution through the development and deployment processes. However, AI systems often require a wider range of skills.
Machine Learning Operations
As an example, MLOps engineers have become pivotal agents of the communication between data science and IT operations. MLOps (Machine Learning Operations) is essentially the DevOps equivalent of AI, focusing on deploying, monitoring, and supporting ML models in production. These skills are in high demand, and the trend is increasing as organizations learn that models require pipelines that can be scaled and ongoing support once they are trained.
Job titles such as “MLOps Engineer”, “Machine Learning Deployment Engineer”, or “AI Platform Engineer” are becoming popular in enterprise recruiting, as such people are needed who are conversant with both the ML algorithms and the infrastructure that must service those algorithms at scale. These experts establish automated processes (to ingest data, retrain a model, CI/CD, etc.) that finally make the so-called last mile of AI projects, the transfer of a promising model on a laptop to a reliable service in production, pass successfully.
Data Engineers
In the same way, data engineers are needed to develop and maintain the data pipelines that we mentioned above. They specialize in collecting, transforming, and making data available to AI systems, with experience in databases, big data tools, and cloud services. Data scientists often struggle to obtain consistent databases or a real-time feeds model for their training, unless they have good dataset engineering.
Machine Learning Engineers
Another important part is Machine Learning engineers or software engineers specializing in ML: they may frequently be the ones who would get the models designed by data scientists and optimize them or re-implement them into production code (e.g., by rewriting a Python proof of concept into a fast Java service).
They also require DevOps and Cloud engineers who will be needed to provision the IT infrastructure (containers, clusters, GPUs, etc.) and plug in AI workloads into the current IT environment. Additionally, an ML architect or AI architect can be instrumental in architecting the entire AI platform, ensuring that all components (data pipelines, model serving, monitoring) are integrated into a coherent blueprint.
AI Product Owners and Translators
In addition to the engineering positions, enterprises must consider roles that bridge the technical and business worlds. An AI Product Owner (or AI Product Manager) is a new type of role that aims at ensuring that AI development is in line with business goals and the needs of users. They provide product vision of AI, prioritize the features and use cases, and align with stakeholders (business leaders, data scientists, and engineers). The product owner in an agile organization plays a crucial role in maximizing the value that the AI solution provides, as the team creates something that will be adopted and solve real problems.
Such people should possess a combination of skills: knowledge of AI capabilities, limitations, domain knowledge, and project management skills. They operate on the backlog of AI capabilities, drive development sprints, and ensure that the AI solution is of high quality and ethically worthy of launching. Practically, the AI product owner may, e.g., collaborate with a fraud analytics team to prioritize the selection of fraud scenarios to address with a model, translate compliance demands to the data scientists, and establish adequate user feedback systems after deploying the model.
Domain Expert or Business Analyst
The other important position is the domain expert or the business analyst, who is a business translator. These individuals possess an in-depth understanding of the business process or domain (finance, supply chain, customer service, etc.) and may be able to assist the AI team in interpreting data properly and framing the problem effectively.
They make sense of the AI outputs within the context and assist in motivating user adoption by clarifying the reasons why the model is recommending something to the business stakeholders. In many cases of successful AI integration projects, there are cross-functional teams where data scientists and engineers collaborate closely with domain experts and product owners to make the solution viable and valuable.
Upskilling and Reskilling
Since there is a need to have AI talent, and the practitioners are few to meet the demand, companies ought to schedule to upskill the current employees besides external recruitment. The single-minded approach of simply hiring unicorn AI talent is impractical and expensive, and according to a single Deloitte report, it is not the silver bullet that will solve the AI skills gap issue. Rather, leaders ought to find existing employees (developers, analysts, IT employees) and train them in data science or MLOps skills and invest in specific training.
An employee of your firm can become a software engineer and learn TensorFlow, becoming a junior ML engineer. A business analyst can learn to use AI tools in the scope of their analysis. A large number of organizations are creating internal AI academies or collaborating with online learning platforms to upskill at scale. In addition, ensure that end-users and business teams are educated on the use of AI systems, including how to interpret AI model outputs and integrate AI-based insights into decision-making processes. Technical skills have a short lifespan in the realm of AI, so make it a culture of constant learning.
In Part 2 of the Playbook, we mention that creating AI learning tracks specific to the roles in development will result in accelerated adoption.
Organization and Culture
To actually get AI into the enterprise, there are organizations that establish AI Centers of Excellence or data science teams to be business consultants to business units. Other organizations incorporate data scientists into departments, but with centralized control over standards. Regardless of the model, ensure strong ownership of AI programs and that teams are supported by top management.
Engaging change management specialists is also a prudent thing to do; these are experts who would assist in driving the organizational change that accompanies AI (process changes, job redefinitions, etc.). These professionals will be able to conduct training, assist in solving employee issues (such as fear of losing jobs to AI), and contribute to the incorporation of new AI systems into the current workflow.
To conclude, the creation of an AI-enabled enterprise needs a multi-disciplinary team. You need to have the data wranglers, model builders, IT operators, and product-minded leaders all working together. Recruiting new talent can be the catalyst to this ability, but do not overlook the development of your internal workforce, since in many cases, your best domain experts and engineers are already within the company, and with the appropriate training, they can become the AI champions you require.
With the correct role formation (such as MLOps engineers and AI product owners) or encouraging cross-team cooperation, you precondition the sustainability of AI integration. The lack of talent is a significant factor, as reported by many companies, which is why they are not adopting AI. They are also trying to improve the situation by balancing external talent with reskilling initiatives. Those who succeed in this field achieve sustainable competitive advantage through their human capital.
Choosing Tools and Platforms: Build vs. Buy vs. Open-Source
Now that the data and people are established, the next set of decisions in front of enterprises concerns tools, platforms, and the architecture of AI. The AI technology landscape is enormous, spanning open-source libraries, cloud services, and turnkey AI systems offered by vendors.
How you build your AI stack can have significant effects on speed, cost, and flexibility. Here, we summarize the key aspects of developing AI capabilities vs. purchasing them, as well as the differences between open-source and proprietary tools.
Build vs. Buy Decisions
Do you develop your own machine learning platform and bespoke tools, or do you buy off-the-shelf (or cloud-managed services)? The real world is like this: most big organizations wind up with a hybrid solution. Meaning a buy-and-build solution, where third-party pieces are integrated into some bespoke in-house solution. A single platform that fits all is seldom, and maybe because every business has different data, business processes, and legacy systems.
Purchasing a commercial AI platform or suite may provide quicker early outcomes and lessen the workload on your internal teams (because the vendor gives you a great deal of functionality that is available out of the box). For instance, numerous vendors provide automated model training, pre-built AI APIs (such as vision and speech), or MLOps pipelines as part of their offerings.
This can get your project started, and you do not need to reinvent the wheel. However, pure “buy” solutions can be inflexible, leading to a vendor roadmap and potential lock-in. On the other hand, self-hosting everything gives you full flexibility to customize it to fit your business requirements; you can customize every part of the stack. However, it also takes a lot of time, talented engineers, and initial capital to get going.
The naive perception is that the buy alternative is a fast start, and may be limited; the build alternative is a perfect fit, but slow and expensive. As a matter of fact, even the purchase of a platform requires some integration work, and construction is often based on the use of open-source tools (which is also a type of buy-in that uses external components).
Building vs. Buying: Crafting a Modular, Flexible AI Stack
The main considerations in the build vs. buy are its internal engineering capabilities, the speed at which you need to bring your product/service to market, the budget, and the strategic value of AI to your core business. A custom platform would be worth the investment when AI is a business differentiator (e.g., you are a technology company or AI is part of your customer offering).
When AI is more of a supplementary capability (let us say, to internal efficiency or analytics), then it may be cheaper to use existing platforms. In many cases, the final result is a modular architecture: you may purchase a data ingestion tool, open-source libraries to do your modeling, and create your own integration layer to bridge to your internal systems.
It is true that most organizations have incorporated various tools instead of using one monolithic platform. An ML platforms report published in 2024 observes that vendors of cloud infrastructure are investing heavily in AI platform services, yet enterprises still have to seam them together with custom tools and their code. The lesson is to be flexible – select best-of-breed components for each task (data pipeline, model development, model serving, monitoring) and make sure they can interface via APIs or standard interfaces. By doing so, you avoid getting stuck and can change parts as technology evolves.
According to Balancing AI Integration Costs: Build From Scratch or Upgrade Existing Systems, many companies use a modular approach — different tools for data ingestion, open-source libraries for modeling, and bespoke layers for integration. This hybrid approach avoids vendor lock-in.
Open-Source vs. Proprietary Tools
The AI community thrives on open-source, utilizing libraries like TensorFlow and PyTorch, as well as tools such as Kubernetes, Apache Kafka, and MLflow. The open-source AI software is free and flexible: you can look at the source code, modify it, and it does not require a license fee in most cases. A lot of innovative research developments (such as some of the large language models) are published as open-source, which enables businesses to experiment without incurring huge expenses.
Experience the Power of Custom Software Development
Transformative Software Solutions for Your Business Needs
Explore Custom SoftwareOpen-source is not, however, free in the sense of the effort that you have to put in deploying and managing it. It requires skilled engineers to deploy and manage, and you do not usually have dedicated support should something go wrong.
An example of this is that running an open-source ML pipeline may involve your team having to provision servers, scale, and merge community updates on your own. The proprietary or commercial AI tools(whether startups or large vendors) can be more turnkey-like, easier to use, and may include even no-code interfaces, and are accompanied by support contracts.
They may cover much of the complexity so that your data scientists or analysts can work on solving business problems instead of spending their time on infrastructure management. In exchange, you have to sacrifice flexibility. Your options are limited to what the platform supports, and you may not be able to customize beyond the features offered.
The best option, in many cases, is to combine the use of both open-source and proprietary tools. For instance, an enterprise can use a proprietary cloud AutoML service to deploy a simple model for a common task quickly. Alternatively, they can utilize open-source libraries to create a custom model tailored to a unique problem.
According to one of the sources, there is “no reason to go all in on proprietary or all in on open source – most enterprises should use both at the same time”. You may use open-source due to flexibility (and because you can avoid license costs) in some areas where you are strong, say, an open-source database or ML framework, but use proprietary solutions where you want speed or convenience, or guaranteed support (an MLops platform in the cloud, or a vendor-provided model with a service SLA).
Open-Source vs. Proprietary AI: Balancing Flexibility, Cost, and Control
The factors to consider when selecting open vs. closed are: the expertise of your team (strong internal AI engineers will be better able to work with open-source), the criticality of the application (mission-critical applications might not be able to leave such work to open-source), the cost model (open-source has a lower initial cost, but potentially higher maintenance costs), and the sensitivity of the data (self-hosting open-source internally may be preferable if you cannot send data to a vendor cloud).
Hybrid Approaches: Best Practices to Avoid AI Stack Lock-In
Finally, here, hybrid strategies are also dominant. Many companies are leveraging managed cloud to run open-source AI software, such as orchestrating open-source model servers on Kubernetes or utilizing cloud GPU instances for open-source LLMs, thereby combining the scale benefits of cloud with the flexibility of open-source. Typically, the initial approach involves using proprietary tools for a rapid pilot of an AI solution, followed by a transition to open-source or custom tools as the use case evolves and requires further customization.
The lesson: don’t decide about pros and cons based on perceptions, but weigh them on their merits, and anticipate that over time and with more AI deployment, you will shift the balance between build vs. buy, open vs. closed. The idea is not to get into analysis paralysis. Instead, just choose a stack that suits your immediate requirements and strategic limitations, but design it in a modular fashion so that you can upgrade it as you go along.
Vendor Selection and Ecosystem
Make sure that you conduct your due diligence when you decide to outsource some of the components. Features and price are important when choosing AI tools. However, it is also about their integration capability, security, compliance (Does their solution meet your data governance requirements?), and roadmap fit.
Experience Expert IT Consultancy
Transformative Strategies for Your Technology Needs
Discover IT ConsultingIn particular, choosing the AI services of one cloud provider over another or the platform of a niche AI startup is a decision that needs to be made based on the ease with which it will be integrated with your data sources and downstream systems. Make sure the vendor does not support open standards (or you will be locked in to the extent of not being able to export your models/data in case you actually need it).
Consider the maturity of the tool. While bleeding-edge startups may offer new capabilities, mature vendors provide a more supported and stable option. Scalability, multi-cloud, or on-prem could be a factor if you need flexibility in deployment (not all companies are willing to be tied to a single cloud provider to manage all AI workloads).
The AI is developing at a rapid pace; therefore, you should also consider the investments the vendor makes in AI research and development. Are they keeping up to date (e.g., new model types, support of transformers, or new capabilities, e.g., explainability)? It would be prudent to start with a proof of concept using a vendor tool (most vendors allow trials) and then, depending on the result and integration effort, take up larger contracts.
Enterprise AI Platforms
One quick overview on “enterprise AI platforms”: many vendors are marketing what they refer to as end-to-end platforms where they do data ingestion, model development, deployment, monitoring, and so forth, all on a single platform. This can be tempting, yet there is one factor that is easy to overlook: there is no such thing as a plug-and-play AI platform. You will be forced to adapt it to your context, and you are probably going to mix multiple tools.
However, an in-house product (home-grown or bespoke) is very useful to ensure that not all the projects are one of a kind. It provides standardization – standard tools, templates, and environments to the AI projects, and is faster and standardizes the best practices (including version control and reproducibility).
This stack would typically require a dedicated team (AI/ML platform team) to maintain in most companies, supporting the rest of the organization’s AI needs. The easiest approach, if you haven’t already, is to standardize simple elements (such as a single code repository for models, a shared feature store, or standardized model deployment pipelines) and then scale up.
Cloud vs. On-Premise vs. Hybrid AI Infrastructure
Many of the infrastructure choices you make are among the largest, such as where to host and execute your AI workloads. There are three broad possibilities now available to enterprises: cloud, on–premises, or a hybrid mix. Both models have their benefits and trade-offs, and the appropriate option depends on aspects such as data security requirements, scaling needs, latency, and cost structure. What are the advantages and disadvantages of these alternatives? Let us compare them and see when each of them is appropriate.
Cloud AI Infrastructure
Cloud platforms (such as AWS, Azure, GCP) offer on-demand access to an immense number of AI services and hardware (fast GPUs/TPUs to train on, and scalable servers to deploy). The main benefits of the cloud are speed and scalability, as you can deploy resources within minutes and scale to large workloads without having to acquire any hardware. It will speed up experimentation with AI and reduce the cost of entry.
A lot of managed solutions (data storage to pre-built AI APIs) are also available via cloud AI services, and can speed up development. Cloud is also opex (pay-as-you-go) based, where there is no huge initial capital investment. Running AI in the cloud can, however, get expensive when done at scale (operation costs can scale with data and usage), so you should know how you will use it over the long term.
In addition, data security and residency issues can be brought up. Whether you have sensitive or regulated data (customer PII, healthcare data, etc.), storing it in the public cloud may also demand rigorous compliance (or may even be prohibited by regulators in some cases).
Cloud also implies less direct control: you hand over uptime and performance to the provider, and you might experience vendor lock-in when you are heavily utilizing their proprietary services. Nonetheless, cloud-first or cloud-only approaches are trendy among enterprises seeking to modernize IT and leverage AI as quickly as possible, especially when initiating new AI projects with minimal legacy integration requirements.
On-Premises AI Infrastructure
On-premise refers to the deployment of AI workloads in your own data centers and on your own hardware (including potentially edge sites in an IoT context). The biggest advantage of on-prem is that you have controlover the environment, which may be essential to security, compliance, or performance. The companies that operate in highly regulated sectors (finance, government, healthcare) usually prefer on-prem or private cloud implementation of AI that uses sensitive data, as they are certain that data cannot leave their regulated facilities. On-prem may also provide better application latency when an application requires real-time processing near the source of the data (such as AI on manufacturing equipment, or an AI-assisted video analytics system in a retail store). Running data on-premises means you do not have to make a round-trip to cloud data centers, which may be fatal in some time-sensitive applications.
Costs of On-Premises AI Infrastructure
Cost-wise, on-premises solutions require capital expenditure, i.e., investment in servers, GPUs, networking, etc.. Still, they can be cheaper for steady, high-volume workloads, assuming you can fully utilize the hardware during its lifetime (as you are not paying a premium to the cloud). With that said, on-prem scaling is more complex (procurement, installation) and will require capacity planning to prevent under-/over-provisioning.
On-prem deployments also place the responsibility on your IT team to handle any hardware failures as well as update software. Maintenance overhead is not negligible – many businesses have miscalculated how difficult it is to maintain a state-of-the-art AI infrastructure (including bespoke cooling/power of GPU clusters, workload scheduling, etc.).
In short, on-prem is best when data control or low latency is paramount, or a long–term cost of a predictable workload makes ownership of hardware preferable. It is not always so good when you require agility or you lack the internal competencies to handle complicated AI stacks at scale.
Hybrid AI Infrastructure
A hybrid model seems to be the best solution for large companies, where they can have both on-premises and cloud resources. A hybrid model could see you retain mission-critical or sensitive AI workloads on-prem (to maintain the highest level of security and control) and use the public cloud to burst or other non-sensitive workloads.
Accelerate Your Growth with Digital Transformation
Digital Excellence Through Customized Business Solutions
Explore Digital TransformationOne example would be an insurance company running models on cloud-hosted data anonymization (leveraging massive compute), but running the inference model in their data center on the customer data. Alternatively, a company may conduct daily analytics on-premises, utilizing cloud consumption during seasonal peaks or for intense experimentation that exceeds internal capacity.
Integration of Hybrid AI Infrastructure
Hybrid models demand careful integration – data must flow (safely) between on-prem and cloud environments. Your teams will have to operate a more complex distributed infrastructure. Containers and Kubernetes, which are modern technologies, have simplified hybrid deployments, as they allow a common layer to run in both environments.
Other organizations have also implemented a multi-cloud approach(multiple cloud providers) as part of a hybrid solution, to prevent vendor lock-in and to take advantage of different strengths (e.g., using one cloud provider’s AI services in natural language processing and another in computer vision, in case they are the best at them).
Flexibility of Hybrid AI Infrastructure
Hybrid’s flexibility means you can optimize workload location (i.e., keep on-prem what has weight (large datasets that are expensive to move, or under residency laws), and burst cloud when you need scale-out compute. It also offers an economical balance: fixed workloads could be put on owned hardware, whereas dynamic workloads on the cloud could provide an economical balance overall.
The challenges involve more complex operations and require strong networking and security across the boundary (to guarantee, e.g., that data in transit between on-prem and cloud is encrypted and that identity/access management is integrated).
To summarize these differences, consider the following comparison:
Comparison of AI Infrastructure Models
| Infrastructure Option | Key Benefits | Key Challenges & Considerations |
| Cloud (Public Cloud AI) | – Rapid deployment and easy startup (no hardware to provision). – Virtually unlimited scalability on demand. – Access to advanced managed AI services and global infrastructure. – OpEx cost model (pay-as-you-go) can lower initial costs. | – Ongoing costs can mount with scale (must monitor ROI).<br>– Less control over environment and potential vendor lock-in.<br>– Data security/privacy concerns if using sensitive data (compliance requirements).<br>– Network latency or bandwidth costs if data transfer to cloud is large. |
| On-Premises(Private Data Center) | – Complete control over data, security, and compliance (data stays in-house). – Can optimize for low latency and high performance (especially with local GPU hardware for real-time needs). – Potentially lower long-term cost for constant high-volume workloads (no vendor premium). – Can leverage existing IT investments and integrate with legacy systems easily. | – High upfront capital investment (hardware, facilities). – Requires specialized IT expertise to manage AI infrastructure (incl. maintenance of GPUs, etc.). – Scaling up is slower and capacity is finite (risk of underutilization or resource crunches). – Innovations in AI (new chips, frameworks) may require frequent upgrades. |
| Hybrid (Cloud + On-Prem) | – Best of both: flexibility to run workloads in optimal location (e.g., sensitive data on-prem, burst compute in cloud). – Improved reliability and disaster recovery (can fall back to alternate environment). – Strategic cost management by allocating stable workloads on-prem and variable demand to cloud. – Avoidance of total vendor lock-in; leverage strengths of multiple platforms. | – Added complexity in deployment and operations (requires orchestration across environments). – Need strong network connectivity and security across on-prem and cloud boundary. – Requires consistent management and monitoring tooling to handle hybrid estate. – Potential data duplication or synchronization efforts to keep environments in sync. |
The vast majority of enterprises are currently moving toward some sort of hybrid cloud for AI unless they have a requirement to be on-prem-only or cloud-only. Indeed, according to surveys in the industry, most people prefer hybrid models, which use the “scale of cloud and security of on-prem.”. For instance, a company may wish to retain its core customer data and sensitive model training on-prem to ensure compliance, while leveraging cloud services for large-scale experiments or to process global inference requests closer to end-users. Even cloud-forward companies might want some parts of it to run on-prem (or at the edge) in cases where low latency is paramount (e.g., AI of autonomous machines or IoT sensors where every millisecond matters).
Decision-Making Criteria
Recommendations for decision criteria in your organization should address: data sensitivity (are there regulations or risk implications to data being off-prem?), performance requirements (do you need to process data locally to achieve high performance?), scale and variability (do workloads spike or are they steady?), cost (have you analyzed 3-5 year TCO of cloud vs buying hardware to meet your use case?), and strategicflexibility (do you want to avoid being dependent on a single infrastructure?). In many cases, it is not an either/or decision, but what is the correct combination. An example would be using the cloud for early development or a pilot due to speed. You may maintain a fixed workload on-prem when it is cost-effective or more secure, but still keep it in sync with the cloud to do backups or other analytics.
When adopting a hybrid approach, also consider the technology that can help make migration and consistency easier. Containerization, multi-cloud management platforms, and infrastructure-as-code are possible ways to make sure your AI workloads are portable and reproducible in different environments. The final objective is infrastructure agility: the capacity to roll out AI where it would make the best sense, without having to re-architect everything per environment.
Implementation Playbook: From PoC to Pilot to Production
Data, teams, and infrastructure are ready; the final step is to execute the AI projects all the way up to production deployment. Here is where businesses often fail to take the next step: moving beyond experiments (Proof-of-Concepts and pilots) to achieve stable, scaled, and integrated AI systems. Indeed, numerous organizations face a problem of “pilot purgatory”, where AI projects fail to progress beyond the pilot phase.
Streamlining Your Path to Effective Product Discovery
Make Your Ideas a Reality in Four Weeks with Our Results-Driven TechBoost Program
See Product Discovery ServicesSurveys have found that approximately two-thirds of companies have not been able to move beyond the stage of AI proof-of-concepts to full production deployments. In another study, it has been discovered that only 4 of 33 AI prototypes become production-ready, and that is an 88% failure-to-deploy rate, which shows how big this challenge is. To prevent such an outcome, it is important to adhere to a formal implementation guide, including software engineering best practices (CI/CD, testing) and ML-specific ones (model validation, monitoring, retraining).
So, what are the stages of AI implementation, and where to go through them:
1. Proof of Concept (PoC)
The Proof of Concept is a narrow-based experiment to confirm that a specified AI solution will be able to address an issue or provide value. This tends to be a small group (data scientist, potentially an engineer, and a business stakeholder) operating on a sample of data to train a model and testing to ascertain whether it passes some threshold of performance. Learning and de-risking are the aims of PoC; you want to have a feel of what can be achieved technically and an early indication of the potential ROI before going all-in. As an example, a PoC may be: Can our customer care data be used to tune a language model to automatically categorize support tickets accurately with 90% accuracy? or Can we train a vision model to detect camera images of product defects with a false negative rate of less than or equal to 5%?
Best practices at PoC stage
Make it time-boxed (a few weeks or months) and to the point. Iterate on cloud resources or sandbox environments (this is where cloud is so flexible, spin up a GPU for a couple of weeks). Record the results and learning. Get business stakeholders involved early on. Ensure that the metrics you aim to achieve are expressed in business terms (e.g., is 90% accuracy truly beneficial, or do they require 99%?). In the case that the PoC outcome is promising, prepare to outline what comes next (what would a pilot look like?) or, in the case it fails, take note of why (was the data lacking? algorithm not advanced enough? business process not ready?). Therefore, either pivot or shelve the idea.
Notably, it is never too early to start considering the end-to-end workflow in a simplistic manner, i.e., how would data reach this model in production? What would we retrain it in case it does work? A lot of PoCs are performed under a vacuum (on a fixed dataset, by a single data scientist) and demonstrate good performance. But fail when it comes to integration since they ignore data pipelines, deployment platforms, or scalability. Use the PoC to determine what it would take to productionize (even though you do not do them just yet).
In short, begin with a time-boxed proof of concept (PoC) for one use case. As stated in Successful Proof of Concept (PoC) in Software: A Step-by-Step Guide, this step is crucial for aligning stakeholders and conducting feasibility checks.
2. Pilot / Prototype Deployment
An AI pilot typically represents the next step beyond PoC, where the model or solution is implemented in a controlled environment and then tested in real-world situations. That could entail rolling out the AI solution to a small section of users, a particular area or branch, or operating it in conjunction with current operations. The initial aim of the pilot is to test the performance at scale, collect the feedback of the users, and identify any integration problems before the full rollout.
To give one example, a bank could conduct a pilot of an AI to detect fraud in 5% of transactions to evaluate its performance and the reaction of fraud analysts to alerts. Alternatively, a retailer may initially test AI demand forecasting on a single product line in one country. Technically, at this point, you are interested in integration: linking the model to live data feeds, hooking it into business processes (through an API or application interface), and making sure it can run consistently (24/7, as may be required).
Key Considerations for Pilots
Mock it up as a small production rollout. Establish success criteria of the pilot (e.g., did the AI system work as accurately with live data? Did it increase the outcome of the process by X per cent? Is it comfortable to end-users (Are end-users comfortable with it)? Focus on system performance, latency, and throughput, and be aware of potential issues like data pipeline failures and model errors. Monitoring on the pilot is also important: record the predictions that are made by the model, monitor any errors, exceptional cases, and be prepared to identify issues early.
Meanwhile, prepare feedback gathering: should the AI be facing customers, get user feedback; should it be inside, interview the people using it (e.g., did the sales team trust the AI recommendations? Is it compatible with the way they work? (Did it suit their workflow?). Such socio-technical feedback is invaluable to hone not only the model but the general solution (the problem is not necessarily the accuracy of the model, but its output presentation or use).
Pilot Integration with Legacy Systems
Integration with legacy systems is one of the challenges that are common among pilots. The PoC could have been its own experiment, but in a pilot, you usually have to hook into existing IT systems (databases, ERP, CRM, etc.). It is here that most pilots get stuck because of unsuspected dependencies or the inability to draw data out of siloed systems. Involving your IT architects and perhaps middleware or APIs may assist. It may involve a negotiation of data access or security approvals to interconnect systems sometimes. It is preferable to test these difficulties in a pilot than in a complete deployment. Organizational resistance is another common problem at this step: front-line workers may be cautious of the AI, or middle managers may be less than persuasive. An executive sponsor and clear messaging about the purpose of the pilot (that it helps, not puts, people out of work) is key to winning cooperation.
MLOps Pipeline & Governance Build
An essential best practice is to use the pilot to also begin developing your MLOps pipeline and governance. For example, start automating some of the workflow. Maybe introduce a rudimentary CI/CD of the model (so that when data scientists make it better, you can redeploy with minimal effort), introduce a model registry, and certainly introduce model monitoring in the pilot environment (monitor predictions vs. outcomes so that you can detect whether you have model drift). Lack of such MLOps practices is one of the main reasons why so many of the AI pilots fail to scale, as they can often work well at first, but then will decay with no mechanisms to detect and repair problems. According to one of the sources, one of the key problems causing failures in the scaling of AI is the absence of strong MLOps and pipeline automation, because MLOps is the framework used to manage the model lifecycle (deployment, monitoring, retraining). Therefore, in a pilot attempt to mimic how you are going to sustain the model in production. E.g., schedule a job to retrain the model when new data has arrived (or at least how you would update it), and watch the results of inference and look out for anomalies.
Pilot’s Duration & Evaluation
Lastly, the pilot should be determined in terms of duration and evaluation. Pilots are supposed to be long enough to experience a realistic variance (e.g., a complete business cycle, or season, where relevant). When you are done, review formally: Has it passed the test to go into production? What changes should be made? Pilots can iterate; you may run a second pilot with those changes incorporated if the first pilot reveals serious problems. But not pilot creep, where it simply runs on without decision; keep in mind the goal is to either move to scale or back to the drawing board.
3. Production Deployment and Scale-Up
Entering production indicates that the AI solution will be fully implemented in the operating environment of the enterprise, will be working with real data round-the-clock, and will be used at a planned level (all users, all business departments, etc.). This stage needs the utmost degree of rigor concerning reliability, efficiency, and governance. You move on to a “critical system” mindset. There are a number of practices and systems that ought to be established:
Robust MLOps & CI/CD
You must have a strong production-ready CI/CD pipeline by the time of production of ML models. This is a pipeline that automates the code/model change-deployment cycle, including testing. As an example, a pipeline may automatically run unit tests, retrain the model on new data, compare it to baseline metrics, and, in the case of success, deploy a new version of the model to production (possibly in a canary release or an A/B test). Automating the release process of AI will guarantee that you can update models on a regular basis (especially important for performance improvement or drift) without time-consuming manual work. According to one of the best practices, “automation of the AI pipeline by using CI/CD is an important aspect of speeding up deployment and having fast, stable updates”. This introduces discipline, similar to standard software deployments, which minimizes human error and accelerates iterations.
Testing & Validation
AI systems are more complicated than conventional software when it comes to testing, but that does not mean that they need less testing. When you come to production, you must not only test the software surrounding the model, but you must also test what the model produces. Define some validation set or acceptance criteria on new versions of the model (e.g., it has to be accurate on a new validation dataset above X, and it cannot get too bad on measures of bias above Y). Check edge cases: e.g., when the model is presented with missing/weird input data, does the system fall over prettily?
When testing integration, ensure that updates to the upstream data schema or API do not break your pipelines. To monitor behavior in a staging environment, many teams use a shadow-mode run of the AI system on real data, before turning it fully on. Also consider ethical and bias testing, where possible, check that the model does not systematically disadvantage a group, or that any regulatory requirements (such as explainability of some of the decisions) are fulfilled. It is important to keep in mind that AI failures during the production stage may be expensive (fiscal and reputation-wise) and thus invest in thorough testing in advance.
Performance Optimization
You need to optimize throughput, latency, and resource utilization in production. It can include things such as engineering work like model compression (to accelerate inference), code optimization (e.g., through vectorized operations or C++ backend), serving infrastructure scaling (load balancing, GPU acceleration where necessary, etc.), and caching/pipelining where possible. In case you are using cloud services, make sure that you configure auto-scaling or proper instance sizes. Pay attention to metrics of the monitoring system: CPU/GPU load, memory consumption, queue, and response times. Performance tuning is usually an iterative process; profile your system to determine the bottlenecks (perhaps the model is fast, but accessing data is slow- then you may need a better data store, or you have to keep data in memory).
Monitoring & Alerting
When the AI systems are in production, monitoring them is imperative. You should observe the technical and business metrics. Technical metrics would be things like system up-time, error rates, and model-specific statistics such as distribution of input data vs. training data (detecting drift), confidence scores of predictions, etc. Business metrics are more about the results: e.g., if it is a recommendation model, what is the click-through or conversion rate? In the case of a forecasting model, how is it influencing inventory levels or costs?
Experience Our Skilled Development Teams
Elevate Your Projects with Skilled Software Development Professionals
Get Your Development TeamInstall some automated alerts that indicate the existence of trouble issues, e.g., when the model error rate or prediction distribution is much further away than the training baseline, or when data pipelines have failed and new data is not flowing in. Among the common things done is the implementation of data drift detectors, which compare the statistics of the incoming live data against the statistics of the training set. Large drift may signal the need to retrain the model or that the quality of the data has changed. It should also monitor upstream and downstream – make sure the data being fed into the model is being updated according to plan, and that any system using the results of the model is receiving it correctly.
Checking Model Drifts
Also, watch out for model drift in outcomes: when you have ground truth coming in with some lag (e.g., real sales that you can compare to a forecast, or real fraud outcomes of your fraud predictions), bring that back in to test the current accuracy of the model. In case the accuracy drops below a certain level, initiate the retraining workflow or investigation. Monitoring dashboards and reporting of model performance to stakeholders at a specified period of time are incorporated in some organizations to ensure transparency. The most successful organizations do not think of model monitoring as an afterthought of the AI system.
Retraining and Model Lifecycle
In contrast to conventional software, a model might lose quality over time due to drifting data or changes in the real world. Consider how you are going to refresh the model. This may be on a schedule basis (retrain weekly/monthly on new data) or condition-based (retrain when performance goes down).
Consider using automated pipelines to retrain your models when possible, but also involve human monitoring (e.g., data scientists should occasionally look at whether the feature set remains relevant or whether concept drift (the relationship between the input and output changes) is occurring). Ensure version control of models and data schemas, as this is useful for auditing and rolling back if a new model version does not perform as expected.
A new best practice is to adopt a model registry and metadata trace of each version of a model, such as the training data used, model parameters, evaluation metrics, etc. So in case something goes wrong, you may see what version of the model you were using and what could have changed.
Governance and Compliance in Production
When you bring AI into production, which affects real customers or critical processes, ensure you comply with all relevant regulations and ethical guidelines. An example is that the GDPR may need to explain algorithmic decisions to EU customers.
Is there a way you can explain what your model outputs, or a different review process? Does the nature of your AI (i.e., making lending decisions or medical diagnoses) mean that you are not in compliance with applicable laws and that there is a “human in the loop” where it is required?
Also, address model risk: there is formal model risk management (MRM) in specific industries (e.g., banking). This may include peer reviews of the models, recording of intended use and limitations, and re-validation regularly. Ensure that ownership of roles is clear, who is the custodian of the model during production, and who will be held responsible in case of failure? The oversight of these aspects is conducted by a committee in some companies, called the AI governance committee.
Scaling Across the Enterprise
Once an application has been successfully produced, scaling can involve expanding to more users, or use case scenarios, or adding more data sources. Go in stages, don’t attempt to big-bang several new use cases at once. Use what you learned during your initial deployment of production to develop a playbook or template for the next. In addition, disseminate success stories internally (to keep the executives on board and leverage it in other departments).
Avoid the proliferation of AI solutions. It is nice when teams are excited, but ensure consistency. Building a duplicate siloed AI in two departments to do the same task is often worse than building one and then reusing the same AI in a different department to solve a similar problem. Here is where your platform team or AI Center of Excellence can help and prevent duplicated work.
Discover more details for a successful implementation in AI Integration for Business: Practical Steps to Implement and Scale.
Case study – Ford Motor Company
Recall the earlier mention of “pilot purgatory”. One such case is the failure by the Ford Motor Company in its quest to implement AI-based predictive maintenance of its fleet cars. Technical PoC looked promising; the AI was able to foresee some component failures up to 10 days before they occurred, and would have been revolutionary in minimizing the time vehicles are out of service. Nevertheless, when the company applied this solution enterprise-wide, it encountered several challenges: the AI integration with legacy dealer maintenance systems proved difficult, dealership personnel were reluctant to adopt the new system, and the pilot did not lead to a successful rollout.
Two years later, the project was still in pilot mode, which demonstrated that implementation of AI may be derailed because of organizational and integration issues, even when the algorithms are functioning correctly. This reflects the value of an implementation playbook that extends beyond a successful model, all the way through to change management, system integration, and user adoption. Operational excellence should be combined with technical excellence to make the AI part of the enterprise fabric.
Drive Continuous Improvement & Business Value in AI Integration
The start of the continuous improvement cycle does not stop with the launch of the AI solution in production. Put in place a cadence to check the performance and consequences of the AI system. As an example, conduct monthly/quarterly reviews where the AI team and the business stakeholders review important metrics, identify any problems, and prioritize improvements. Loop back to the user: user feedback or the mistakes the model made should be used to feed back into the model or the data (perhaps new features or additional training examples). You may also discover new use cases or features later that you can add to the AI system to develop it further and benefit the business.
Identify Opportunities for Expansion
And keep up to date on the fast-moving field of AI, maybe some newer algorithms will help your model be more accurate or efficient. An advanced model from two years ago may be overtaken by a new approach today; therefore, prepare an incremental model update if necessary. By that, it is not meant to pursue every new and shiny thing but to consider whether significant gains may be obtained (e.g., many organizations began with classical ML models but later switched to deep learning or transformer-based models as they became feasible, and provided better results, such as in NLP).
Share Success & Build AI Culture
Last but not least, celebrate and spread the word on successes: Showing business value (cost savings, revenue gains, customer satisfaction improvements, etc.) of your AI in production will entrench support of additional AI integration. It will also assist in creating an environment in which AI is regarded as a reliable partner in the enterprise and not a science experiment.
Key Takeaways
- Data Readiness is Paramount: Quality data that has been prepared is going to be what makes it successful to integrate AI into the enterprise. Invest in data cleaning, pipelines, labeling, and governance before it becomes a garbage-in, garbage-out problem. Data as a strategic asset – Data should be treated as an asset that is aligned to use cases, continuously monitored for quality, and has clear governance policies.
- Empower a Cross-Functional AI Team: The AI solutions created must be created at scale, and a diverse team is required, including data engineers, data scientists, ML/Ops engineers, software developers, and AI product owners, and they are all important. Close talent shortages through intelligent hiring (MLOps and ML engineering are in demand), as well as through employee upskilling. Engage business domain experts to facilitate and lead AI initiatives, ensuring they are successful and sustainable.
- Leverage the Right Tools and Platforms: AI does not have a one-size-fits-all platform, and most organizations integrate open-source tools and vendor solutions to design a custom stack. Make build vs. buy decisions based on your abilities and requirements, and don’t hesitate to consider a hybrid model. Open-source is flexible (and cost-effective), and proprietary services can speed up deployment, and a combination of the two can be highly effective.
- Choose Infrastructure Strategically: Depending on the sensitivity of data, performance, scalability, and cost, cloud, on-premise, or hybrid infrastructure should be selected. Cloud has rapid service deployment and unlimited scale, which is good when you need to experiment and have variable workloads. On-premises has low latency and control, which is preferable for sensitive data and consistent large-scale workloads. To balance these, popular hybrid models store critical data on-prem and burst to the cloud for computation. Pursue infrastructure agility since AI workloads should be allowed to run where they best fit as your needs change.
- Establish an AI Delivery Pipeline (PoC → Production): Use this gradual process, starting with micro proof-of-concepts to validate an idea, then graduating to pilot deployment to test integration in real life, and finally transitioning to production with full MLOps vigor. At every level, there should be clear success criteria, and stakeholders must be involved. Implement CI/CD for AI and robust MLOps to automate model deployment and updates. Don’t leave potential pilots to rot; tackle the typical areas where pilots fail (data problems, integration challenges, lack of ownership) before they even get to the pilot stage.
- Monitor, Maintain, and Govern AI Systems: AI is a long-term commitment. Monitor production models 24 hours a day, focusing on their performance, drift, and data pipeline health. Compute on regular retraining or model improvements due to the change in data and conditions. Enforce good governance on ethical use, compliance, and risk management of AI decisions. By viewing AI models as living beings that require care and development, enterprises can achieve and maintain the value they receive from AI over the long term, potentially increasing it.
In the above areas, such as data basis, team abilities, technology choice, and execution with discipline, enterprises have a far greater likelihood of the success of the AI integration. In Part 3 of this playbook, we have seen how we created and deployed infrastructure on the AI in a step-by-step fashion. In the following section, we will be talking about scaling these capabilities throughout the organization and combining AI with business practices to bring about transformative results. When properly deployed with the proper infrastructure, it will not be experimental anymore by the organizations, and the AI will become a reality of the enterprise as a competitive advantage.
How much does enterprise AI integration typically cost?
Depending on the scope of what an AI integrator is required to do, AI integration may cost between 50,000 and 1 million dollars on a pilot project versus a large-scale implementation with complex infrastructure and bespoke models. These factors are the volume and complexity of data, platform decision (build or buy), cloud-based architecture, staffing, and compliance with regulations. Scalable MLOps, retraining pipelines, and model governance are also investments that can increase costs but are guaranteed to be successful over the long term.
What hidden costs should we expect in AI implementation?
In addition to model development, costs for data cleaning, pipeline design, labeling, synthetic data generation, and model drift detection are hidden. Cloud usage fees, security controls, legacy system integration, and vendor lock-in mitigation are other cost drivers. They frequently manifest during the pilot-to-production transition or when AI workloads are scaled larger than originally expected.
Does company size affect AI infrastructure choices and cost?
Yes. Small enterprises tend to use cloud-first strategies to reduce CapEx, whereas large corporations tend to invest in hybrid or on-premise infrastructure to gain more control and data security. Prices depend on AI maturity: small companies can pay $20-100K for MVPs, whereas international corporations can invest more than $500K in modular AI platforms that can be integrated into their current IT systems.
How long does it take to move from PoC to full AI deployment?
A minimum proof-of-concept (PoC) could take 4-8 weeks. The pilot can take 3-6 months to run, and a full-scale production deployment can take 6- 12+ months when combined with enterprise systems and infrastructure. The timelines are based on the complexity of the use cases, the availability of the data, the integration readiness, and the alignment of the technical and business teams.
What are the stages of successful AI deployment?
The three key stages are:
- Proof of Concept (PoC): Inquires whether AI is capable of addressing a problem of interest with sample data.
- Pilot: It is a small-scale release to the field to implement performance, integration, and user reaction.
- Production: CI/CD pipelines, monitoring, governance, and retraining to scale deployments. The stages must be time-based, quantitative KPIs, and both technical and business stakeholders must be engaged.
Why do so many AI pilots fail to scale into production?
Some common blockers include: the absence of robust data pipelines, manual processes, end-user resistance, and insufficient model monitoring or retraining plans. Several PoCs have been designed in isolation—they do not yet consider real-time data flows, deployment infrastructure, or how the AI fits into everyday operations. Misalignment and resistance to change in organizations are also factors that derail promising pilots.
Should we build our AI platform or buy off-the-shelf tools?
When AI is a fundamental differentiator, a custom stack offers greater control and longer-term scalability. When AI is used to facilitate internal processes (e.g., document processing, demand forecasting), ready-made solutions or cloud-based APIs deliver faster time-to-value. A hybrid stack is chosen by most businesses, as it involves off-the-shelf, open-source, and custom connectors.
What is the difference between open-source and proprietary AI tools?
The open-source tools (e.g., TensorFlow, MLflow) are flexible, cheaper, and can have access to innovative technology- it is also necessary to have good internal knowledge. Proprietary tools provide support and integration, out-of-the-box features, and friendliness- but can put you in a lock-in. Some of the most successful AI stacks are capable of doing both: e.g., open-source for experimentation, and proprietary for scaling to deployments and support.
How should we choose between cloud, on-premise, or hybrid AI infrastructure?
- Cloud is best used in fast experimentation, elasticity, and SaaS-like deployments.
- Regulated industries or low-latency applications, or in applications where sensitive data cannot exist outside company systems, are better on-premise.
- Hybrid provides an ideal combination of cloud and on-premises resources: cloud for compute-intensive tasks and on-premises for data control.
The decision you make should be well-balanced across data sensitivity, performance, scalability, and long-term cost structure.
What roles are essential in an enterprise AI team?
An effective AI team will incorporate:
- Data Engineers – develop scalable data pipelines.
- MLOps Engineers – automated deployment and monitoring.
- ML Engineers – an optimized operation of models.
- AI Product Owners – make sure it aligns with the business objectives.
- Domain Experts – put in context and determine results.
- Software Engineers – develop models for the systems.
This partnership guarantees an accurate, usable, and scaled-up model of yours.
What roles are essential in an enterprise AI team?
MLOps is a form of machine learning automation (in the DevOps style). It ensures models can be deployed, versioned, monitored, and updated automatically. MLOps allows AI systems to be brittle, slow, and hard to scale. It is particularly important in regulated industries or in application scenarios where data is frequently updated.
How often should AI models be updated or retrained?
AI models can be retrained in case:
- New data considerably alter the input distribution (data drift).
- The model begins to have poor performance (performance drift).
- Business objectives or governmental laws change.
Most businesses retrain monthly or quarterly, though the application determines this. Automated retraining pipelines help balance performance and cost.
Why is data readiness crucial for successful AI integration?
The AI models will produce inaccurate or erroneous results because of the absence of high-quality, consistent, and publicly available data. The saying “garbage in, garbage out” is particularly true in AI. Data preparedness consists of data cleansing, data integration, annotation, and governance. It is the least recognized yet most important step in AI implementation.
How can we promote AI adoption across the organization?
Technical success is not all that is needed to be adopted. Build trust by:
- Proving quantifiable business value.
- Engaging business users at the early stages.
- Creating end-user training on AI interpretation and application. Rewarding success stories within the company.
Culture matters. An effective change management plan is the only thing that can make AI a reliable, enterprise-wide solution rather than an IT experiment.
How do we monitor and maintain AI systems after deployment?
Continued success will be based on visibility and automation. Monitor using monitoring dashboards:
- Model performance metrics
- During drift: Training and live data.
- System uptime and latency
Apply alerting, version control, retraining processes, and documentation. A monitoring system should include governance and compliance, at least in areas of regulation, such as finance, health, or insurance.