Business leaders frequently encounter terms such as “data warehouse” and “data lake” as they develop their data strategy. While these ideas might be advanced, it’s necessary to understand them to make good decisions about your data. This resource simplifies the concepts of data warehouses and data lakes, highlighting the differences in their structure, cost, application areas, and performance. It also includes real-world cases and practical instructions on selecting the proper database for a business.
What Is a Data Warehouse (in Plain English)?
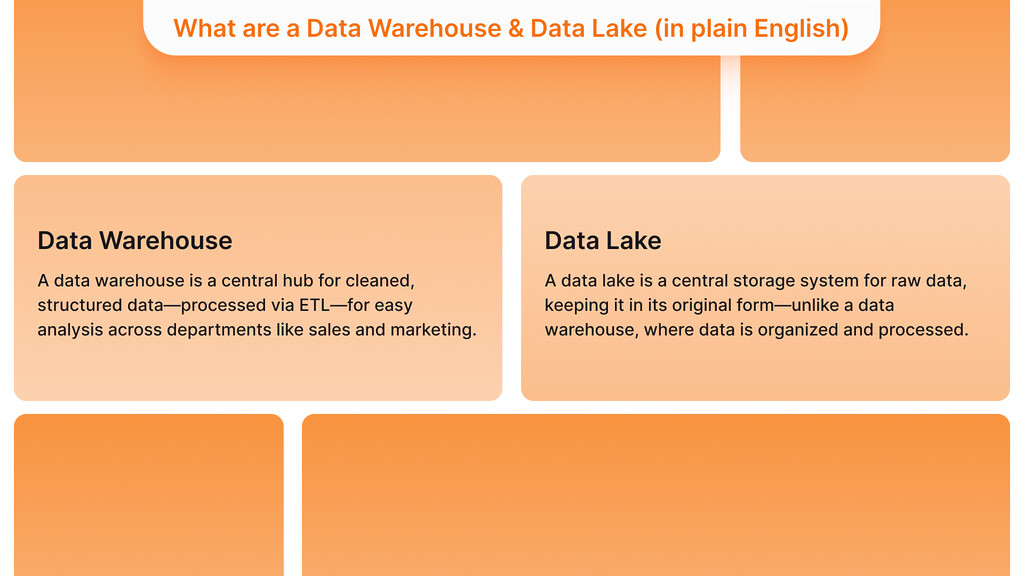
A data warehouse is similar to a well-organized library full of data. It serves as a primary location to store data that has been processed, sorted, and organized for a specific purpose. Typically, data is processed through an ETL (Extract, Transform, Load) process before being stored in a warehouse. As a result, data from sales, marketing, and customer service is pulled in, organized, and formatted, and then saved in the warehouse.
Experience the Power of Custom Software Development
Transformative Software Solutions for Your Business Needs
Explore Custom SoftwareWhat makes up the core features of a data warehouse?
- Structured Data Only: The information in a data warehouse is organized to fit within a predefined structure or design. Picture data is being placed in labeled shelves, with each point stored appropriately.
- Purpose-Built for Analysis: The data in a warehouse is set up to meet the needs of analysis and reporting. In this example, a warehouse may review historical sales data to inform the production of business performance reports each quarter.
- Immediate Usefulness: Since data preparation occurs before storage, analysts and business users can utilize the data immediately and obtain consistent results. You can use it right away to develop reports, dashboards, and insights.
- Examples of Data Warehouse Platforms: Popular Data Warehouse Platforms include Snowflake (accessible in the cloud) and Amazon Redshift, as well as Google BigQuery. They work diligently to organize data effectively and enhance the speed of data searches.
In essence, a data warehouse takes data that is already structured and accessible, enabling managers and executives to make informed decisions more easily. Salesforce enables quick responses to questions and reporting, so when you ask about our sales by region for the last quarter, you receive a prompt answer since the data is already organized for that specific question.
What Is a Data Lake (in Plain English)?
A data lake is like a big pool where all your data can be stored in one place. It functions as a main system for storing data in its original state. Data in a data warehouse is organized, while in a data lake, data is placed in its original form, just as it arrives.
What makes a data lake unique?
- Stores All Types of Data: Data lakes are designed to hold any type of data, such as tables, logs, images, email, and text. No rules dictate the exact shape the data has to be in before it’s stored. As a result, a data lake can contain transaction logs from customers, content from social media sites, and videos.
- Schema on Read (Flexibility): All data is initially stored in a data lake, and you shape it as needed when you use it. It is referred to as “schema-on-read.” You can use it to process any data as soon as it is entered, quickly. You interpret and structure your data only when it has been retrieved for analysis. As an example, you could collect all the website clickstream information in a lake and only organize some of it when you need to answer a marketing question.
- Highly Scalable and Cost-Effective: Data lakes are constructed on budget-friendly storage that can easily handle massive amounts of data. Using cloud services like Amazon S3 as the main storage for a data lake is a choice many companies make, thanks to its nearly unlimited space and the ability to control costs. Since you don’t have to process the raw data, it is often less expensive to keep it in a lake compared to a warehouse.
- Examples of Data Lake Platforms: Many organizations select cloud services to build their data lakes. Many people use AWS S3 because it is highly durable and scalable, along with AWS Lake Formation and AWS Glue to manage and list data in data lakes. Both Microsoft Azure and Google Cloud have Data Lake Storage as their primary data lake service.
A data lake is a centralized repository where all your information is stored, eliminating the need for manual organization. It’s perfect for collecting lots of data, and you decide how to use it when needed. As a result, data lakes are highly flexible, as you can add more data later on. This also means that if you want to work with your data, you may need to hire data specialists, as it is not already set up.
Primary Differences Between Data Warehouses and Data Lakes

Both data warehouses and data lakes store large amounts of data, but their structures, uses, costs, and performance differ significantly. Let’s take a look at this comparison chart to notice the differences:
Data Structure & Schema
Data Warehouse: The schema is defined when the data is first loaded. The schema must be set up before saving any data. Data must match a predefined model (configuration) to be accepted into the warehouse. As a result, all data in the warehouse is organized, uniform, and prepared for analysis.
A Data Lake relies on the schema-on-read method. You use a schema to organize your data after it has been stored. The lake receives data in any format, structured or unstructured, and does not transform it upon entrance. You save everything you find now and figure out its use after you have collected it.
Data Preparation & Processing
A Data Warehouse is formed by running ETL (Extract, Transform, Load). Before going into the warehouse, the data is processed (cleaned and organized). This way, the warehouse maintains high-quality data that is crucial for addressing specific business inquiries. It takes longer to load the data initially, but once it’s in the system, analysis can be performed quickly.
Accelerate Your Growth with IT Consultancy
Propel Your Business with Expert Tech Insights
Discover IT ConsultingA Data Lake commonly uses ELT (Extract, Load, Transform). Data files are retrieved from the staging area and placed in the lake without being processed. The transformation occurs only when necessary. The initial loading is swift and allows for immediate data collection, but you must perform the transformation job when running the query or copying the data to a warehouse or another system.
Users & Accessibility
Data Warehouse: Created so that business analysts, managers, and non-technical people can work with the data themselves. Data in a warehouse is already structured to respond to typical business questions, allowing users with some analytical knowledge to query the warehouse using dashboards or SQL tools for insights. It is straightforward to use for reporting on KPIs, trends, and the company’s past performance.
Primarily, data scientists and data engineers are the main users of the Data Lake. Because data is often raw, it typically requires someone with technical skills to process and interpret it. They analyze data in the lake using programming and modern technologies to gain new insights. A data scientist could analyze data stored in a data lake by studying log files to find patterns or build a machine learning algorithm.
Use Cases
Using a Data Warehouse is typically the best approach for generating reports and accessing business intelligence (BI). It works exceptionally well when you need to analyze reports, sales dashboards, monitor inventory, or perform quick and repeated queries on old data. Because warehouses are home to clean data, they’re perfect for answering common questions (e.g., sales per region for the quarter or how customer numbers have changed from last year to this year).
The Data Lake is the ideal solution for handling large datasets, facilitating data exploration, and leveraging machine learning. In situations where you have vast data with unstructured parts, data lakes are effective. For example, when analyzing customer feedback on social media, utilizing IoT data for preventive maintenance, or retaining clickstream data for future use. They are helpful when you want to maintain the data for now and consider a way to utilize it later, which helps with innovation and yields unexpected discoveries.
Performance (Query Speed)
Typically, a Data Warehouse enables faster querying of structured data. Since the data is set up for efficient analysis, answering questions like “What was the revenue for last month by each product category?” happens very fast. They are designed to provide quick answers when you have a large amount of well-organized data.
With Data Lake, querying may require more time for raw data. As data lakes store data as it arrives, performing complex analysis often requires reviewing large datasets and transforming unstructured data into valuable information during the processing stage. Without indexes or specific schemas, finding the answer to “How many times did a user click X on our website?” means going through extensive log files, which takes time. New technology and the idea of a data lakehouse are helping, but typically, data lakes are not as fast for structured queries as warehouses.
Cost
Keeping data in a Data Warehouse is often more expensive, both in terms of storage and processing. Because warehouses are designed for fast access, they incur costly storage and preprocessing of their data. When using cloud data warehouses, you may incur costs for the computing power required to process and analyze your data. As data accumulates, it is important to maintain the warehouse to keep it efficient. To summarize, you must spend more for stronger performance and better structure.
Data Lake: Saves you money by allowing you to store more data in one place. The fact that you can access inexpensive storage (such as cloud object storage) and don’t perform extensive processing on every incoming data makes data lakes a good choice for storing a large amount of information at a low cost. For this reason, companies often store data on a lake rather than on disk storage, since it’s more cost-effective. Still, remember that while data storage is affordable, you’ll face higher costs when using the data for insights (which requires computing power).
Governance & Security
The structure of the Data Warehouse facilitates easier management of security and adherence to rules. You are aware of the data you have and its position in the schema. Tools have been developed to control user access to tables or columns and oversee the use of data. As a result, warehouses are simpler to maintain for compliance purposes (such as GDPR) and prevent unauthorized access to data.
Governance in a Data Lake is often more difficult. A lack of proper management can make a data lake turn into a messy “data swamp.” Keeping track of the data in the lake, ensuring its accuracy, and determining who is authorized to access it requires powerful data cataloging and governance tools. Data lakes are becoming increasingly secure over time, yet they are often perceived as less secure when unmanaged due to the diverse range of data they contain. Businesses that build data lakes utilize additional tools to record, manage access to, and track the use of data, thereby mitigating risks.
To summarize these differences succinctly:
- Data warehouses = Structured, cleaned data for quick analysis and BI; higher cost but high performance; used by analysts and business users.
- Data lakes = Raw, all-encompassing data storage for flexibility and advanced analytics; lower cost to store; used by data scientists and engineers; potentially slower for standard queries.
Real-World Examples and Scenarios
Relating these concepts to practical situations can help people grasp them more clearly. The following examples are easy to follow:
Data Warehouse Example – Snowflake at a Retail Chain
Imagine a large retailer that seeks to see all sales, inventory, and customer loyalty data in one place. They can achieve this by using a data warehouse (Snowflake or Amazon Redshift) to get data from point-of-sale systems, their inventory databases, and customer rewards programs, clean and organize it, and put it all in one place. Since the data warehouse is suitable for these queries, executives and store managers can swiftly create reports on weekly store sales, inventory turnover, or customer analysis. All sales and inventory information is collected in the warehouse, which supports decisions regarding stocking and pricing adjustments.
Data Lake Example – AWS S3 Data Lake for a Tech Company
For example, suppose a tech company offers a mobile app and reviews user activity, generates app logs, collects feedback from customers, and tracks social media chatter. These data types (structured tables, semi-structured logs, unstructured text, images, etc.) can be simply stored in an Amazon S3 data lake. Raw data is stored indefinitely in the data lake, as it is both cost-effective and scalable. If the company decides to find answers to new questions, it can easily pull data from the lake and analyze it. For example, a data scientist can review log files to spot usage patterns leading up to a rare app crash, or a marketing analyst can examine social media comments and app usage. It works just like having a sandbox for ideas: everything is stored in the data lake, and specialists can extract the data they need. If data from the lake is required for frequent reports, it could eventually be moved to a warehouse to speed up access.
Mobile App Development for a Competitive Edge
Developing Mobile Apps that Engage Your Customers with Your Brand
Explore Mobile App DevelopmentHybrid Use Case – Both Lake and Warehouse (Lakehouse Approach)
Many companies find that combining the two approaches is most effective. Uber, for instance, collects the raw information from all the rides taken (including details of locations and drivers) in a data lake, and data scientists review it to identify ways to improve route and pricing efficiency. Operations managers can also benefit from data warehouses, which provide them with quick daily updates on key metrics, such as trip numbers or the company’s finances. Likewise, Airbnb accesses key business metrics, such as occupancy and trends, from its data warehouse and utilizes data lakes to analyze raw data, refine its search functions, and enhance user experiences. Combining these methods enables them to enjoy the flexibility and depth of the lake, as well as the speed and dependability of the warehouse.
When to Choose a Data Warehouse vs. a Data Lake
Deciding between a data warehouse and a data lake (or choosing to use both) comes down to your business needs and strategy. Here are some guidelines to help business leaders make this decision:
Choose a Data Warehouse if:
Your top priority is to have quick analysis and reporting on structured data. If daily or weekly dashboards and reports (covering financial, key performance, and operational statistics) are needed by executives and managers for reliable and quick access, a warehouse is usually the best solution.
You are familiar with the data inside and out and have clear questions that need to be addressed. For example, if your focus is on sales by region or seeing the results of your marketing campaigns, a warehouse will store and deliver the data you need.
Data privacy and meeting regulations are your main concerns, and you’re working with structured data such as financial information or customer records. Advanced security measures and tight monitoring of products entering the warehouse can help the company maintain compliance.
An example would be a healthcare company using a data warehouse to consolidate patient visit data, treatment outcomes, and billing information into a standardized format. As a result, non-technical administrators can produce reports that enhance operations while still respecting data privacy rules on an organized set of information.
Choose a Data Lake if:
There is a vast amount of data, and you need an affordable way to save it all. If your company gathers data that could be helpful someday, a lake helps you retain it without deciding upfront what to do with it.
You already have a team of data scientists or want to conduct advanced analytics or machine learning. For these use cases to succeed, they rely on having a large amount of raw data. Thanks to a data lake, these professionals can examine raw data to identify patterns or train their models (for example, they can utilize extensive historical click data to enhance a recommendation engine or leverage sensor data to anticipate equipment failures).
It is essential to be able to adjust and adapt how you utilize your data. If your business world changes rapidly and you might need to access new data, a lake can be set up and used much more quickly than a warehouse. As soon as you begin collecting data in a lake, you can work on finding its value as your needs change.
For example, a media streaming company can track when users pause, rewind or skip what they are watching. Event data that is not organized can be stored in a lake. Having studied the data, data scientists can introduce new options, such as personalized show suggestions or enhanced app screens, based on user actions. While the company still needs to decide on the questions for the data, keeping it in a lake allows them to explore many possibilities.
Consider Using Both (Hybrid Approach) if:
Your data strategy is designed to address current business intelligence and to support future data initiatives as well. Many companies maintain data warehouses for daily reporting and compliance while utilizing data lakes for data analysis, data storage, and future use.
The first step is to gather all data in the data lake, and then, important, valuable data is transferred and processed in the warehouse. While some modern architectures refer to this as a “data lakehouse” for when the technology is blended, organizationally, it means you can use both types of storage together, as needed.
If you are considering a hybrid setup, ensure you manage data effectively to maintain order in the lake and have a plan for transferring the relevant data into the warehouse for analysis.
For an example of semi-structured document handling with automation, Hypersense explains how AWS tools enhance data lake workflows in Intelligent Document Processing on AWS – Workflow Automation.
Business Impact & Decision Considerations
- Always align with business objectives: When speed is crucial, consider storing your data in a warehouse. If you want to work with data for the long term and gain significant value, choose a lake.
- Consider the skills of your team: If not, a data lake could remain unused or become a confusing mess. A data warehouse can be leveraged quickly to support the current team of analysts. Alternatively, advanced teams may struggle to innovate with data if your company doesn’t utilize a data lake.
- Budget and Cost Tolerance: When using a data lake, storing data is often less expensive, but when you need to process that data, costs may arise. Not only do data warehouses incur costs to build, but they also often require additional compute resources over time. Besides storage, evaluate the costs of system management, tools, and the bills from the cloud service provider.
- Regulatory Environment: If you operate in an industry with stringent regulations, such as finance or healthcare, a data warehouse can streamline compliance. Still, you can use a data lake, but you’ll have to add extra governance.
Making the Right Choice for Your Business
Instead of considering data warehouses and data lakes as rivals in technology, non-technical executives and business owners should view them as having distinct purposes. Everything in a data warehouse is arranged and presented in a way that makes it simple to find what you’re looking for. Like a big storage warehouse, a data lake holds everything you collect, so you can see and use valuable data when you need it.
When you aim to help your team through easy and accurate reports and when you depend on solid information for daily decisions, a data warehouse is likely the top choice. You can trust your data to remain consistent and perform optimally for your business’s needs.
If you want to leverage big data to advance your company, benefit from advanced analytics, or remain cost-effective by saving data, a data lake can be highly beneficial. It ensures you are ready for the future by preserving all your data and supporting the experimentation that may discover new product benefits or help you save time with AI.
Many successful organizations begin by collecting all data in their data lake and then transferring the processed data to data warehouses for easy access by everyone. You don’t have to favor one over the other; instead, use the mix that best fits your plan.
In short, keep in mind the goal of the business: what changes or improvements do you hope to make with data? The answer will determine whether just a data warehouse, just a data lake, or both is the best choice. When you know these concepts in simple terms, you can be confident discussing them with your IT and data teams and ensure your technology investments support the company’s objectives.
IT Consultancy for Strategic Advantage
Tailored IT Solutions to Drive Your Business Forward
Discover IT ConsultingContact us today to future-proof your data infrastructure.
What is the difference between a data warehouse and a data lake?
A data warehouse is developed to store structured data that has been optimized and cleansed for reporting. In contrast, a data lake is used to store raw, unstructured, and semi-structured data for future use. Data warehouses operate on a schema-on-write model: data is designed and then stored on disk. Schema-on-read Data lakes are more flexible and less expensive to get started, particularly for big data projects or machine learning.
What is a data lakehouse, and how is it different?
A data lakehouse is an amalgamation of a data warehouse and a data lake in terms of abilities. It enables companies to store any type of information in raw format and perform quick analysis using a structured query. This hybrid model will minimise data duplication and provide a single architecture for both reporting and AI use cases.
When should I use a data warehouse instead of a data lake?
A data warehouse should be used when the organization requires quick, predictable reporting on structured data. It is best suited for finance, sales, and operations teams that need to monitor KPIs, create dashboards, or comply with standardized reporting mandates.
What are the benefits of using a data lake?
A data lake is flexible and cost-efficient, storing large volumes of data in raw form, including logs, videos, and clickstream data. It is particularly helpful when companies invest in data science, machine learning, or future use-case exploration, and when flexibility is paramount.
Can I use both a data lake and a data warehouse together?
Yes. A common approach among many businesses is a hybrid strategy, in which raw data is stored in a lake and processed data is transferred to a warehouse for further analysis. This is both agile to innovation and high-performance to day-to-day reporting – otherwise known as a “lakehouse” architecture.
What is the cost difference between a data lake and a data warehouse?
It is also because data lakes are cheaper to store large amounts of data, given the low cost of cloud storage (e.g., Amazon S3). Processing requirements and structured storage make data warehouses more expensive, but they are faster for analytics than data stores. When processing data in a lake, processing costs increase with each query or transformation.
What types of data can be stored in a data lake?
A data lake can store structured, semi-structured, and unstructured data, including spreadsheets, JSON logs, images, PDFs, audio, video, and IoT sensor data. This places it in useful cases where it is used, such as when there is flexibility or mixed content ingestion.
Who uses data warehouses vs. data lakes?
Non-technical users and business analysts value data warehouses for their rapid access to clean reports and dashboards. Data scientists and engineers who require raw data to perform complex analyses, make predictions, or conduct experiments are the typical users of data lakes.
What’s better for machine learning: a data warehouse or a data lake?
Machine learning is better suited to data lakes, which store raw, diverse data needed to train a model. They complement data exploration, labeling, and feature extraction processes required in AI pipelines. Experimentation should be done with data warehouses because they are more structured than unstructured reporting.
What is ETL, and how does this relate to data lakes and data warehouses?
Data warehouses use ETL (Extract, Transform, Load), with data cleansed before storage. Data lakes use ELT (Extract, Load, Transform) to store data initially and transform it on demand. ETL provides a more structured approach, whereas ELT offers greater flexibility for complex or evolving data.
How does query performance differ between data lakes and data warehouses?
Data warehouses enable efficient, rapid querying of organized data. Data lakes also tend to be slow to respond to queries, particularly when handling unstructured data, because data must be read and processed on demand. The newer lakehouse models are bridging this divide by enabling quick querying of raw data.
Which cloud platforms support data lakes and data warehouses?
Both are supported with Amazon Web Services (AWS), Microsoft Azure, and Google Cloud. AWS has Redshift (warehouse) and S3 (lake); Azure has Synapse Analytics and Data Lake storage; Google Cloud has BigQuery and Cloud Storage. Many businesses combine such services based on need.