Video processing software has become a crucial feature for every social media app. Given that an image is worth a thousand words and a video, on average, contains 30 images per second, these short clips influence various sectors such as entertainment, politics, and both public and private domains. The popularity of media-focused social networks like Snapchat and Instagram highlights the increasing user preference for enhanced images and videos.
Cutting-Edge Mobile App Development for Success
Mobile Solutions that Connect Your Business with Your Market
Explore Mobile App DevelopmentHyperSense has been at the forefront of social media development since 2012. Our first application, iFlipBook, paved the way for expanded expertise, leading to the 2015 launch of MyBlender. MyBlender is a powerful mobile app for iOS and Android that offers professional-level video processing software, rivaling thate of Adobe Premiere.
In this whitepaper, we provide a comprehensive overview of developing a mobile video processing software. This is a must for anyone looking into social media app development, as image and video processing are vital cornerstones to your app’s success. If you have any questions, please feel free to contact us, and we’ll be happy to assist you.
Social Media App Development: Image Processing
Digital image processing involves applying sets of algorithms to modify image pixels. Video processing is similar, as it entails applying the same algorithms to each video frame. These processing phases optimize images or videos, add visual effects, and encode and compress media resources to make them accessible on various platforms, such as mobile devices, desktops, and wearables.
Design for Success with Stunning UX/UI From Our Team
Investing in UX Design Can Yield a Return of Up to $100 for Every $1 Spent
Discover UI/UX DesignFilters are the general term used for sets of algorithms that modify images. Filters alter image information based on a given algorithm, taking an image and a modification rule as input. To simplify, an image is a matrix of pixels, each with a specific color. Filters process a set of pixels and output a new pixel after processing.
Filters can be applied at both GPU and CPU levels. However, GPU filters, called shaders, are more efficient in terms of speed. Shaders are limited in the number of operations allowed and are designed to be fast. Real-time shaders are considered more valuable.
Image processing involves two steps:
- Modifying pixel color
- Modifying pixel position
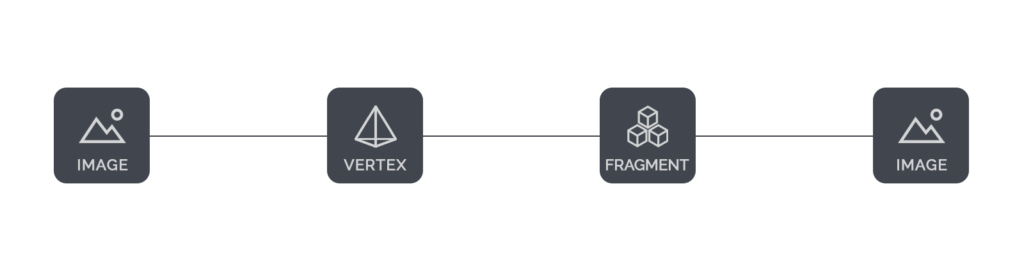
Modifying pixel positions results in rotations, scale changes, translations, and image puzzles (referred to as Vertex). Modifying pixel color can create grayscale images, color overlays, contrast changes, highlights, and more (referred to as Fragments).
A simple vertex is:
attribute vec4 position;
attribute vec2 inputTextureCoordinate;
varying vec2 textureCoordinate;
void main()
{
gl_Position = position;
textureCoordinate = inputTextureCoordinate;
}
This doesn’t change the coordinates of the pixels, leaving each pixel in its original position.
The aforementioned vertex, combined with the following fragment:
precision highp float;
varying lowp vec2 textureCoordinate; // New
uniform sampler2D srcTexture1; // New
const vec3 W = vec3(0.2125, 0.7154, 0.0721);
void main()
{
vec4 textureColor = texture2D(srcTexture1, textureCoordinate);
float luminance = dot(textureColor.rgb, W);
gl_FragColor = vec4(vec3(luminance), textureColor.a);
}
Will result in a black and white version of the original image.
.png)
More complex shaders can use several image inputs. For example, you can overlay 2 images or stitch images one next to the other. The principle remains the same, the vertex will dictate the position for each pixel, while the fragment will specify the colour of the pixel.
For example, if we want to add a sticker on top of an image we must:
- make sure the images have the same size or set the position of the sticker on the larger image;
- leave each pixel in its original position using a variation of the vertex above that has 2 inputs (one for each image);
- set the colour merge of the pixels using the sticker’s alpha as a priority: original_rgb * (1-sticker_alpha) + sticker_rgb * sticker_alpha
Once you understand image processing, you can move on to processing videos. In the end, image and video processing go hand-in-hand because the video process is just working with more images (if you ignore video compression, memory management, multithreading, working with camera framebuffers, etc.).
Social Media App Development: Video processing
A video is a collection of images displayed in sequence, creating the illusion of motion. On average, if a human is shown 30 images per second, the brain interprets them as motion. Videos can be composed of individual images shown in order, but this approach would require a significant amount of storage space. Video encoding reduces storage requirements, but it means that videos need to be decoded before processing.
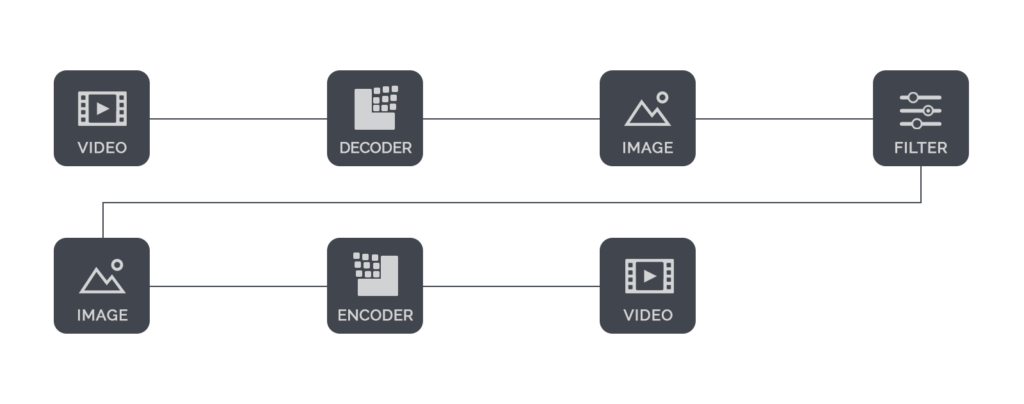
Similar to image processing, video processing can have one or more inputs. The diagram above does not cover all video processing possibilities. For instance, it can create a black-and-white video, but it would be mute.
Experience Our Research & Development Expertise
R&D-Led Software Development Integrates Innovation into Every Product Detail
Learn About R&D ServicesAdding sound changes the diagram and introduces common sound filters such as volume adjustments. Additional sound sources, like background music, can be added as well.
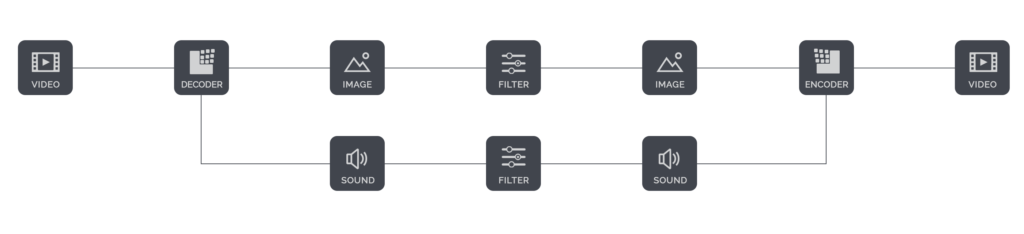
The most common sound filters are volume adjustments.
.png)
Several additional sound sources can be added. For example, you can add background music.
Another crucial aspect of video processing is timing. For example, two videos can be processed in several different ways, such as video1-video2, video1-overlap-video2, or video1+video2. Timing also applies to the video’s sound, like adjusting volume during overlaps to distinguish both audio tracks.
Videos, in most encodings, have no alpha channel, making all pixels opaque. This is done to optimize the video file’s size. Some video effects do not require alpha channels, such as displaying a video on top of another, displaying videos side by side, or playing videos sequentially with various transitions between them.
To accommodate effects requiring alpha channels, various workarounds are employed, including chroma key and track matte techniques. Chroma key uses a specific color (usually green) to dictate the alpha value; the closer a pixel is to this color, the higher the alpha will be during the processing phase. Track matte uses a black and white matrix alongside the two videos. For example, if the matrix pixel is white, the pixel from video 1 will be returned; if it’s black, the pixel from video 2 will be returned, and any other variation will result in a merge.

Understanding image processing is the foundation for processing videos. In other words, image and video processing are vital for any social media app development roadmap. In the process of mobile app development, you will need to factor in the smartphone’s capability and utilize image and video processing software that provides an easy user experience.
Experience Expert IT Consultancy
Transformative Strategies for Your Technology Needs
Discover IT ConsultingIn conclusion, advanced image and video processing software on mobile devices enables the development of high-quality, visually captivating social media apps that cater to users’ increasing demand for enhanced visuals and experiences. Over time, you will need to incorporate other features like video streaming app development into your plans to further meet user demands. These techniques and technologies have revolutionized the way people share and interact with multimedia content on social media platforms, and it’s only possible with the right tech professionals.